R 사용자라면 벡터(Vector)의 개념을 잘 이해하고 있는 것이 필수적입니다. R에서 벡터란 하나의 타입으로 지정된 데이터의 집합이라고 할 수 있습니다.
1. 벡터의 특징
- 한 가지 데이터 타입으로 저장 가능
- 기본적으로 열벡터 형태로 저장됨
- 벡터 연산으로 빠르게 처리 가능
2. 벡터 생성
벡터를 생성할 때는 c(...) 라는 문법을 사용합니다.
각 데이터 타입별 벡터를 생성해보겠습니다.
| # 1,2,3,4로 구성된 숫자형 벡터 생성 numeric_vector <- c(1,2,3,4) numeric_vector [1] 1 2 3 4 # class 함수를 이용하여 데이터의 속성 파악하기 class(numeric_vector) [1] "numeric" # 문자형 벡터 생성 character_vector <- c("one", "two", "three", "four") character_vector [1] "one" "two" "three" "four" # class 함수를 이용하여 데이터의 속성 파악하기 class(character_vector) [1] "character" |
만약 숫자형과 문자형 원소를 묶어서 벡터 생성한다면 그 결과는 문자형 벡터입니다.
| #숫자형, 문자형 원소를 포함한 벡터 생성 mix_vector<- c(1, 2, "three", "four") mix_vector [1] "1" "2" "three" "four" # class 함수를 이용하여 데이터의 속성 파악하기 class(mix_vector) [1] "character" |
3. 벡터 원소 추출하기
3.1. 벡터의 단일 원소 추출하기
벡터의 원소를 추출할 시에는 [ ] 안에 각 요소의 색인을 적어 추출할 수 있습니다.
| test <- c('x','y','z') test[1] # test의 첫번째 요소 반환 [1] "x" test[2] # test의 두번째 요소 반환 [1] "y" test[3] # test의 세번째 요소 반환 [1] "z" |
3.2. 벡터의 여러 요소 추출하기
여러개의 요소를 한 번에 가져오려면 [ ] 안에 색인 벡터를 넣습니다.
| test[c(1, 3)] # test의 첫번째, 세번째 요소 반환 [1] "x" "z" test[c(1, 2)] # test의 첫번째, 두번째 요소 반환 |
3.3. 벡터의 특정 요소 제외
벡터에서 특정 요소만 제외하여 추출하고 싶은 경우 [-색인 ] 형태로 씁니다.
| test[-1] [1] "y" "z" test[-2] [1] "x" "z" |
4. 벡터의 길이
벡터의 길이는 length 함수를 통해 알 수 있습니다.
| length(test) [1] 3 |
5. 벡터 연산
5.1. 벡터 연산자 종류
| 연산자 | 설명 | 결과값 |
| A==B | 벡터 A와 B의 각 요소가 동일한지 판단함 | 진리값의 벡터 |
| A!=B | 벡터 A와 B의 각 요소가 다른지 판단함 | 진리값의 벡터 |
| A %in% B | 벡터 B에 A의 요소가 있는지 판단함 | 진리값의 벡터 |
| test <- c("x", "y", "z") test2 <- c("x", "yy", "z") # test와 test2의 요소가 같은지 확인 test == test2 [1] TRUE FALSE TRUE # test와 test2의 요소가 다른지 확인 test != test2 [1] FALSE TRUE FALSE # test2의 각 요소에 test의 요소가 저장되어 있는지 확인 test %in% test2 [1] TRUE FALSE TRUE |
만약 두 벡터의 길이가 같지 않다면 ==, !=로 연산할 때 오류가 나진 않지만 경고메시지가 뜹니다.
| test3 <- c( "f", "y", "z", "zz") test == test3 [1] FALSE TRUE TRUE FALSE 경고메시지(들): In test == test3 : 두 객체의 길이가 서로 배수관계에 있지 않습니다 |
5.2. %in% 연산자를 활용한 결과값 반환
%in% 연산자는 각 벡터의 순서에 따라 결과값이 달라지기 때문에 혼동하는 경우가 많습니다. 두 벡터의 길이가 다를 경우 %in% 연산자를 사용한 결과의 벡터 길이는 달라질 수 있습니다.
 # 벡터 test3에 test의 각 요소가 들어있는지 판단함 # 길이가 3인 논리값의 벡터 반환 test %in% test3 [1] FALSE TRUE TRUE |
 # 벡터 test에 test3의 각 요소가 들어있는지 판단함 |
이번엔 좀 다른 경우를 보자면 test4 라는 데이터를 생성해봅시다. test4에는 각 원소가 z, x, y 순서로 존재합니다. 이 때 %in% 와 ==의 결과를 비교해봅시다. %in% 연산자는 뒤 쪽의 벡터에 앞 쪽 벡터의 각 원소가 '존재' 하는지를 판단합니다. 즉, 벡터 원소의 순서에 영향을 받지 않습니다.
== 연산자는 각 위치(색인)에 있는 원소를 비교합니다. 즉, 원소의 순서에 영향을 받습니다.
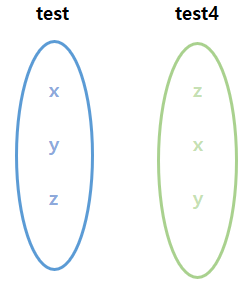 test4 <- c("z", "x", "y") |
벡터 연산 중에서 개인적으로 %in% 연산자를 활용하는 것에 어려움을 겪어본 경험이 많았습니다. 그래서 내용 중에 %in% 연산자를 비중있게 다뤄보았는데, 혹시 어려운 점이 있다면 댓글로 남겨주세요.
6. 벡터를 이용한 데이터프레임 생성하기
벡터는 열(column)을 기준으로 생성됩니다.
이는 데이터프레임을 생성할 때도 적용됩니다.
아래에서 두 벡터를 생성하고 데이터프레임을 생성하면 열 기준으로 만들어집니다.
| vector_1 <- c(11, 22, 33, 44) vector_2 <- c(55, 66, 77, 88) test_data <- data.frame(vector_1, vector_2) test_data  # 벡터를 전치하면 1행 4열의 행렬(matrix)이 생성 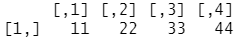
|
7. 다수의 벡터를 하나의 벡터로 합치기
위에서 생성된 vector_1 과 vector_2 를 하나의 벡터로 합치고 싶습니다.
이때 특별히 어떤 함수를 이용할 필요 없습니다.
c()를 사용합니다!
| vector_total <- c(vector_1, vector_2) vector_total  |
'데이터 분석 > R 데이터 처리 & 분석' 카테고리의 다른 글
| [R] 엑셀 파일 불러오기와 저장하기 (xls, xlsx) (3) | 2020.12.25 |
|---|---|
| [R] 반복문 사용하기 (for, while, break, next) (0) | 2020.10.27 |
| [R] tidyr 패키지를 이용한 데이터 재구조(pivot_longer, pivot_wider) (0) | 2020.10.02 |
| [R] 쉼표(comma , )로 구분된 데이터 정제하기 (0) | 2020.09.30 |
| [R데이터분석] R which 함수 파헤치기 (0) | 2020.07.15 |