데이터처리를 하다보면 쉼표( , )로 구분된 문자열을 볼 수 있습니다.
예를 들어, 아래와 같이 쉼표로 구분된 과일명의 데이터가 있다고 합시다.
A, B, C 각 대상자가 가지고 있는 과일 종류의 개수가 몇인지 알고 싶다면 이대로 분석을 하기엔 어렵습니다.
데이터 양이 작다면 하나씩 세도 되지만, 그 양이 많아진다면 난감하겠죠?
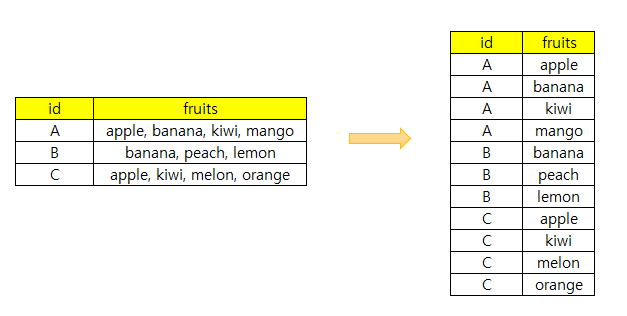
목표는 왼쪽에 있는 데이터를 오른쪽으로 바꾸는 것입니다.
보아하니 쉼표로 구분된 형태보다 우측 데이터로 형태로 변형하면 분석하기 쉬워질 것 같습니다.
변형을 하는 방법이 몇 가지 있으니 간단히 소개하겠습니다.
1.데이터 생성
| test <- data.frame(id=c('A','B','C'), fruits= c('apple, banana, kiwi, mango', 'banana, peach, lemon', 'apple, kiwi, melon, orange')) test id fruits 1 A apple, banana, kiwi, mango 2 B banana, peach, lemon 3 C apple, kiwi, melon, orange |
2. separate 함수 사용
separate 함수는 tidyr 패키지 안에 있는 함수입니다. 문자열이 있는 칼럼을 여러개의 칼럼으로 나타내줍니다.
먼저 tidyr 패키지가 설치되어 있지 않으면 install.package('tidyr') 을 입력하여 설치합니다.
2.1. Arguments
separate(
data, #data frame
col, #적용될 칼럼
into, # 새로 만들어진 칼럼의 이름 정하기
sep = "[^[:alnum:]]+", #구분자
...
)
2.2. Practice
2.2.1. 문자열을 구분하여 새로운 칼럼 만들기
|
test1<-test %>% separate(col = 'fruits', into = c('var1','var2','var3','var4')) # col 인자에 'fruits' 라는 칼럼명을 넣고 # into 인자에 새로 생성될 데이터프레임의 칼럼명을 지정합니다.
test1 id var1 var2 var3 var4
|
여기에서 id기준으로 long format 형태로 바꾸어야 하는데, reshape2 패키지의 melt함수와 tidyr 패키지의 pivot_longer 함수를 쓸 수 있습니다. 두 함수를 각각 이용하겠습니다. reshape2 패키지가 설치되어 있지 않다면 install.packages("reshape2") 를 입력하여 설치합니다.
2.2.2. reshape2::melt
개인적인 생각으로는 melt가 '녹이다' 라는 뜻을 가지고 있는데 아마 wide format의 자료는 많은 칼럼이 있기 때문에 이를 long format으로 변형시킬 시에 여러 변수들이 녹아 없어진다는 의미에서 착안한 이름 같습니다.
|
test1 %>% melt(id.vars='id') # id.vars 인자에 'id'를 줍니다. # 여기에서 'id'는 test1 데이터의 id라는 변수명입니다. id variable value |
이렇게 보니 데이터가 정리되지 않는 것 같은 느낌이네요.
id를 기준으로 정렬하고 value에 있는 NA를 지우면 더 깔끔하게 나올 것 같네요.
참고로 NA가 존재시에 melt함수에 na.rm=TRUE 이라는 인자로 지울 수도 있습니다.
여기에서는 filter함수를 이용하여 지워보겠습니다.
| test1 %>% melt(id.vars='id') %>% arrange(id) %>% filter(!is.na(value)) %>% select(id,value) id value 1 A apple 2 A banana 3 A kiwi 4 A mango 5 B banana 6 B peach 7 B lemon 8 C apple 9 C kiwi 10 C melon 11 C orange |
2.2.3. tidyr::pivot_longer
두 번째는 tidyr의 pivot_longer함수를 이용하는 것입니다. 동일 패키지에 비슷한 기능을 하는 gather라는 함수가 있습니다. 업데이트를 거듭하면서 tidyr에서는 gather 함수의 업데이트를 중지하교 pivot_longer 함수를 권장하고 있습니다.
(Development on gather() is complete, and for new code we recommend switching to pivot_longer(), which is easier to use, more featureful, and still under active development)
pivot_longer(
data, #데이터
cols, # long format으로 변형될 칼럼
names_to = "name",
values_to = "value",
values_drop_na = FALSE,
...
)
| test2 <- test1 %>% pivot_longer(cols=-id) %>% select(id,value) test2 # -id 는 id를 기준으로 long format으로 바꾼다는 의미입니다. # 만약 변형될 칼럼을 이용한다면 cols 인자에 var1:var4를 입력합니다. ex)pivot_longer(cols=var1:var4) id value 1 A apple 2 A banana 3 A kiwi 4 A mango 5 B banana 6 B peach 7 B lemon 8 C apple 9 C kiwi 10 C melon 11 C orange |
위 결과를 보면 앞선 예제와 같이 value칼럼에 NA가 있네요.
filter(!is.na(value))를 이용해서 지울 수 있지만 여기서는 values_drop_na=TRUE 를 이용합시다.
결과는 NA인 행이 지워집니다.
| test2<- test1 %>% pivot_longer(cols=-id, values_drop_na=TRUE) %>% select(id,value) test2 id value 1 A apple 2 A banana 3 A kiwi 4 A mango 5 B banana 6 B peach 7 B lemon 8 C apple 9 C kiwi 10 C melon 11 C orange |
마지막으로 id별 그룹을 지어 개수를 세면 됩니다.
| test2 %>% group_by(id) %>% tally id n 1 A 4 2 B 3 3 C 4 |
3. 요약
- separate 함수를 이용해 구분자가 있는 문자열 데이터의 새로운 칼럼들을 생성
- 생성된 칼럼에 대해 reshape2::melt 또는 tidyr::pivot_longer 함수를 사용하여 long format 형태로 바꿈
'데이터 분석 > R 데이터 처리 & 분석' 카테고리의 다른 글
| [R] 벡터 생성과 인덱싱(Indexing) 및 추출 (0) | 2020.10.06 |
|---|---|
| [R] tidyr 패키지를 이용한 데이터 재구조(pivot_longer, pivot_wider) (0) | 2020.10.02 |
| [R데이터분석] R which 함수 파헤치기 (0) | 2020.07.15 |
| [R데이터분석] R 특정 문자열을 포함한 변수 선택하기 (0) | 2020.07.12 |
| [R데이터분석] 간단하게 변수 이름 변경하기 (0) | 2020.07.10 |