1. pivot_longer : 데이터를 long format 으로 변경합니다. 즉, 행 수를 늘리고 열 수를 줄입니다.
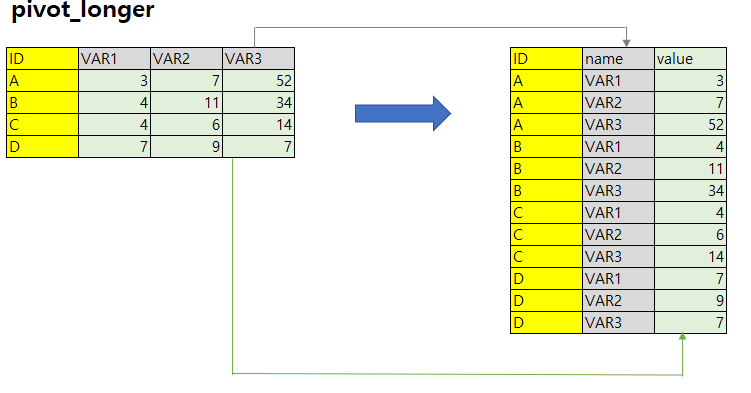
1.1. 용법
pivot_longer(
data, # data frame
cols, # long format 으로 재구조할 칼럼
names_to = "name", # 재구조화된 항목의 칼럼명
values_to = "value", # 재구조화된 수치의 칼럼명
names_sep = NULL # names_to 에 여러 정보를 포함할 경우, 구분자를 기준으로 칼럼 이름을 분할하는 인자
values_drop_na = FALSE, # 결측치 존재시 포함여부
...
)
1.2. 적용
tidyr의 기본 내장 데이터인 relig_income에는 특정 종교가 있는 사람들의 연간 수입에 대한 빈도 수 정보가 있습니다.
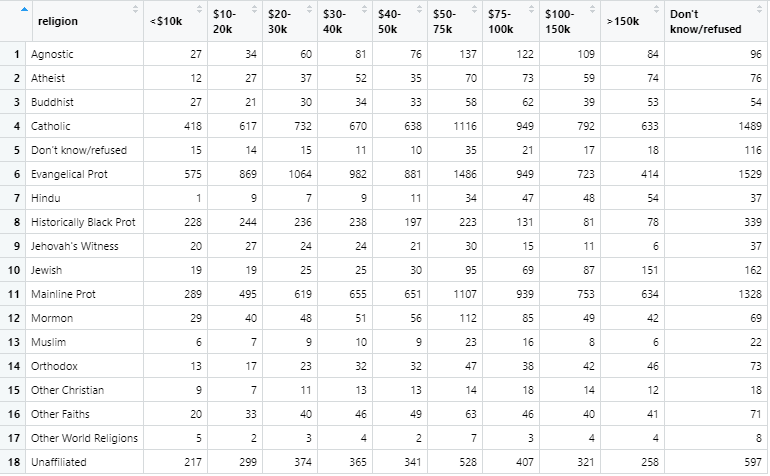
가장 왼쪽 칼럼에 종교가 있고 나머지 칼럼에는 연간 소득 정보가 있습니다. 가장 오른쪽 칼럼에는 모르거나 응답을 거부한 빈도 수입니다. 이 때 연간 소득의 정보를 하나의 칼럼에 몰아서 넣는다면 아래와 같은 형태가 될 것입니다.
| religion | annual_income | freq |
pivot_longer함수를이용해서 위와 같이 세 개의 칼럼 형태로 표현하는 것은 다음과 같습니다.
| long_data <- pivot_longer(data=relig_income, cols=-religion, names_to = 'annual_income', values_to = 'freq') # data 인자: relig_income # cols 인자: religion 이라는 칼럼명을 기준으로 데이터 재구조화함. # 앞에 - 가 붙은 건 해당 칼럼을 기준으로 재구조화한다는 뜻입니다. long_data  |
1.3. 구분자를 기준으로 나누어서 칼럼 생성하기
iris는 다음과 같은 데이터를 가지고 있습니다.

이제 이 데이터를 아래와 같이 .(dot)을 기준으로 분할하여 변수를 나누어서 만들어봅시다.
| Species | name | name1 | value |
| setosa | Sepal | Length | 5.1 |
| setosa | Sepal | Width | 3.5 |
| setosa | Petal | Length | 1.4 |
| pivot_longer(data=iris, cols=Sepal.Length:Petal.Width, names_to=c("name","name1"), names_sep ='\\.') # names_sep 인자에 .(dot) 을 기준으로 분함 # .(dot)을 인식시키기 위해서 앞에 \\ 을 입력함 # names_to 인자에 분할될 변수명을 정함  |
2. pivot_wider : 데이터를 wide format 으로 변경합니다. 즉, 행 수를 줄이고 열 수를 늘립니다.

2.1. 용법
pivot_wider는 pivot_longer의 반대 개념인 함수입니다. 위의 pivot_longer를 통해 나온 결과를 다시 원데이터의 형태로 되돌릴 수 있습니다.
pivot_wider(
data, # data frame
names_from = name, # 현재 데이터에서 함수를 적용했을 때 칼럼명으로 갈 칼럼
values_from = value, # 현재 데이터에서 함수를 적용했을 때 값으로 들어갈 칼럼
values_fill = NULL, # 결측값이 있을 때 대체할 값
values_fn = NULL, # 값에 적용할 함수
...
)
2.2. 단일 칼럼에 값이 있을 때 적용
위에서 만들어 놓은 long_data 라는 데이터를 pivot_wider 함수에 적용하면 원래 데이터로 되돌릴 수 있습니다.
| wide_data <- pivot_wider(data=long_data, names_from=annual_income, values_from =freq) # data 인자: long_data # names_from: annual_income(적용될 칼럼) # values_from: freq(값으로 들어갈 칼럼) wide_data  |
2.3. 다수의 칼럼에 값이 있을 때 적용
tidyr의 us_rent_income은 값이 estiamte열과 moe열이 있습니다.
위에서 본 예는 단일칼럼에 값이 있었지만 이번에는 두 개의 열에 있어서, valuse_from 인자에 두 변수를 지정해주어야 합니다.
us_rent_income wide_us <- pivot_wider(data=us_rent_income, names_from=variable, values_from=c(estimate, moe)) # values_from 인자에 c(estimate, moe) 를 지정해줍니다. wide_us  |
2.4. 결과 데이터에 적용될 함수
pivot_wider 함수의 values_fn 인자에는 결과 데이터에 적용될 함수를 쓸 수 있습니다.
iris 데이터에서 종별로 평균값을 내고 싶다고 한다면 다음과 같이 적용할 수 있습니다.
| long_iris <- iris %>% pivot_longer(cols=-Species) long_iris  long_iris %>% pivot_wider(names_from=name, values_from = value, values_fn=mean) 
|
'데이터 분석 > R 데이터 처리 & 분석' 카테고리의 다른 글
| [R] 반복문 사용하기 (for, while, break, next) (0) | 2020.10.27 |
|---|---|
| [R] 벡터 생성과 인덱싱(Indexing) 및 추출 (0) | 2020.10.06 |
| [R] 쉼표(comma , )로 구분된 데이터 정제하기 (0) | 2020.09.30 |
| [R데이터분석] R which 함수 파헤치기 (0) | 2020.07.15 |
| [R데이터분석] R 특정 문자열을 포함한 변수 선택하기 (0) | 2020.07.12 |