separate_longer_delim 함수 (구분자로 된 변수 처리하기)
1. 구분자(콤마, 빈칸 등)로 구분된 데이터셋
아래 그림처럼 데이터셋에 구분자가 포함된 변수들이 있습니다. 이 데이터셋은 각각의 사람이 어떤 과일을 좋아하는지를 나타낸 것입니다.

Q) 만약 성별에 따라 어떤 과일을 좋아하는지 빈도를 구하려면?
table() 함수를 이용해서 빈도 수를 구할 수 있습니다. 하지만 이 상태에서는 table 함수를 쓰면.. 안됩니다. 왜냐하면 콤마를 포함해서 한 문자열로 인식하기 때문에 각각의 과일 구분이 어렵습니다.
이 형태가 각 과일과 성별에 대한 빈도표입니다.
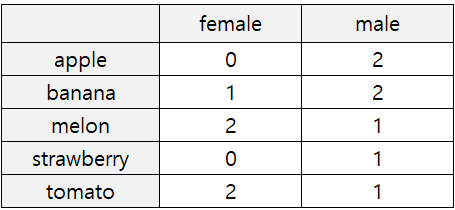
빈도표를 만들기 위해 데이터셋을 long format으로 만들어주는 과정이 필요합니다.

이 작업을 일일히 하기 어렵습니다. 이 때 꽤 좋은 해결 방법이 있습니다.
2. separate_longer_delim 함수 (tidyr 패키지)
tidyr 패키지의 separate_longer_delim를 사용하기 위해 아래 인자(arguments)를 알아야 합니다.

data 인자는 함수를 적용할 데이터프레임
cols 인자는 여러 개 행으로 구분할 컬럼명
delim 인자는 문자열을 구분하는 구분자
| # 데이터셋 생성 df <- data.frame( name = c("A", "B", "C", "D", "E"), height = c(172, 167, 196, 180, 150), sex = c("male", "female", "female", "female", "male"), fruits = c("apple, melon, banana, tomato", "melon, banana", "tomato", "melon, tomato", "apple, strawberry, banana")) print(df)  # tidyr 설치, 불러오기 install.packages(tidyr) library(tidyr) df2 <- separate_longer_delim( data = df, # data 인자에 생성된 데이터프레임(df) cols = fruits, # 여러 개의 행으로 반환될 컬럼명(fruits) delim = ", " # 과일이 콤마로 나뉘어져 있음 -> 주의: 문자이므로 따옴표를 꼭 표시 ) print(df2) 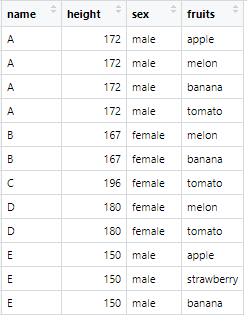 table(df2$fruits,df2$sex)  |
3. 특수문자로 구분된 데이터 다루기
이번엔 꽤나 복잡한 특수문자로 구분된 데이터를 처리해보겠습니다.
잘 이해가 안되면 이 부분을 스킵해도 무방합니다.
| df3 <- data.frame( name = c("A", "B", "C", "D", "E"), height = c(172, 167, 196, 180, 150), sex = c("male", "female", "female", "female", "male"), fruits = c("apple/)(*&^%$#@!, melon, banana** tomato", "melon/ banana", "tomato", "melon& tomato", "apple,^&%$ strawberry, banana")) print(df3)  |
위 fruits 변수를 보면 난감합니다. 과일들이 제멋대로 나뉘어져 있거든요. 이때는 함수를 적용하기 전에 미리 전처리 과정이 필요합니다. 어떤 함수를 쓰든 그에 맞는 데이터셋 구조로 변경해야 합니다. separate_longer_delim 함수를 이용하기 위해서 각 과일이 구분자로 나뉘어져 있어야 합니다. 그런데 fruits 변수에서... 여러 특수문자와 심지어 공백이 여러 개가 있네요. 이제 과일 사이사이에 구분자를 통일해줄거에요.
아래 세 단계에 거쳐 진행될 것입니다.
| 1) 여러 특수문자를 제거하고 2) 여러 공백을 단 하나로만 바꾸고 3) separate_longer_delim 함수를 적용 |
step 1. 특수문자를 없애기
특수문자를 제거하기 위해서 문자열을 대체하는 기능인 gsub 함수를 이용합니다.
gsub 함수는 문자열의 패턴을 찾아 다른 문자로 교체하는 기능입니다.
gsub(pattern, replacement, x)
- pattern 인자는 문자열벡터(x)에서 대체될 패턴 (character string to be replaced ㅑㅜ)
- replacement 인자는 대체할 문자 (character as a replacement)
- x 인자는 문자열 벡터 (character vector)
간단한 예를 들면
| gsub(pattern = "f", # 대체될 문자 replacement = "zz", #대체할 문자 x = c("fpp",'fff','ffaaz','f0f1cz') # 문자열 벡터 ) [1] "zzpp" "zzzzzz" "zzzzaaz" "zz0zz1cz" # 특수문자 없애기 test_fruits <- gsub(pattern = "[!@#$%^&*()/,]", #특수문자를 삽입 replacement = "", # 대체할 문자는 따옴표를 두번 쳐서 아무것도 없는 것으로 변경 x = df3$fruits # df3 데이터셋의 fruits 변수 ) print(test_fruits) [1] "apple melon banana tomato" "melon banana" "tomato" "melon tomato" "apple strawberry banana" *** pattern 인자에서 쓰인 특수문자들은 정규표현식이라는 것의 내용 중 일부입니다. 특수문자열들은 대괄호에 의해 "또는"이라는 의미로 쓰였습니다. 정규표현식은 여기서 다루기엔 쉽지 않은 내용이므로 생략하겠습니다. 대괄호([ ])가 있으면 그 안에 있는 문자들은 "또는" 이라는 의미로 쓰입니다. 예를 들어, a[bc]z는 abz 또는 acz입니다. |
step 2. 여러 개 공백을 하나의 공백으로 바꾸기
다 된 것처럼 보이지만.. 공백이 하나가 아닌 곳이 있습니다. 띄어쓰기(공백)도 한 개, 두 개, 세 개 등등은 각각의 문자로 인식합니다. 그래서 여러 공백이 있는 부분을 딱 하나로 바꿀 것입니다.
| # 여러 개 공백을 하나의 공백으로 바꾸기 # 마찬가지로 gsub 함수를 이용 test_fruits2 <- gsub(pattern = "\\s+", replacement = " ", # 공백 하나로 변경 x = test_fruits) 여러 공백이 한 개로 변경됐습니다. print(test_fruits2) [1] "apple melon banana tomato" "melon banana" "tomato" "melon tomato" "apple strawberry banana" pattern 인자에서 \s+는 반복되는 공백을 의미하는 것으로만 알아두시면 됩니다. 위와 마찬가지로 정규표현식 중 일부입니다. |
step 3. separate_longer_delim 함수 이용하기
# 이 전에 생성한 df3$fruits는 특수문자가 섞인 변수들로 구성되어 있었죠. # df3의 fruits 변수를 위에서 생성한 test_fruits2의 값으로 변경합니다. df3$fruits <- test_fruits2 df4 <- separate_longer_delim(data = df3, cols = fruits, delim=" " # 공백 하나로 구분자 ) df4의 결과를 보면.. print(df4)  # df4의 결과를 이용해서 table 함수로 빈도표 작성 table(df4$fruits, df4$sex)  |
이번 포스팅이 도움이 되었으면 좋겠습니다
'데이터 분석 > R 데이터 처리 & 분석' 카테고리의 다른 글
| [R] merge 함수를 이용한 조인 (데이터셋 결합) (1) | 2023.05.16 |
|---|---|
| [R] duplicated 함수 끝내기 (중복 데이터 확인하기) (0) | 2023.03.21 |
| [R] seq 함수 (숫자 연속으로 나열하기) (0) | 2022.09.30 |
| [R] rep 함수 (반복적으로 값 산출하기) (0) | 2022.07.03 |
| [R] 작업 디렉토리에서 파일 찾기 및 변수 할당하기 (0) | 2021.11.04 |