
이번에 소개할 함수는 arrange, mutate 함수입니다.
arrange 함수는 데이터를 정렬할 때 쓰이며, mutate는 새로운 변수를 추가할 때 이용합니다.
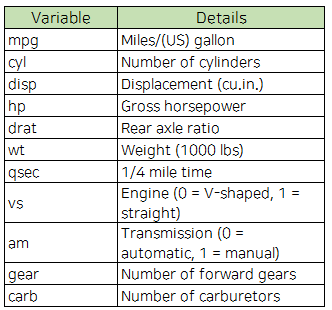
R 기본 내장 데이터인 mtcars 에 적용해보겠습니다. 이 데이터는 1974 년 Motor Trend US 잡지에서 발췌되었으며 연료 소비량과 자동차 디자인 및 성능에 관한 자동차의 10 가지 특징과 32 대의 자동차 (1973-74 모델)로 구성되어 있습니다. 이 데이터셋은 32개의 11개의 숫자형 변수로 이루어져 있습니다.

만약 연비 순으로 정렬하여 자동차의 리스트를 보고 싶다면 다음과 같이 입력합니다.
mtcars %>% arrange(mpg)

mpg 순으로 정렬을 하고나니 행별로 이름이 붙어있었던 게 숫자로 바뀌었습니다!!
이 문제를 해결하기 위해서 tibble 패키지에 있는 rownames_to_column() 함수를 이용합니다.
mtcars %>% tibble::rownames_to_column('mtcars') %>% arrange(mpg)

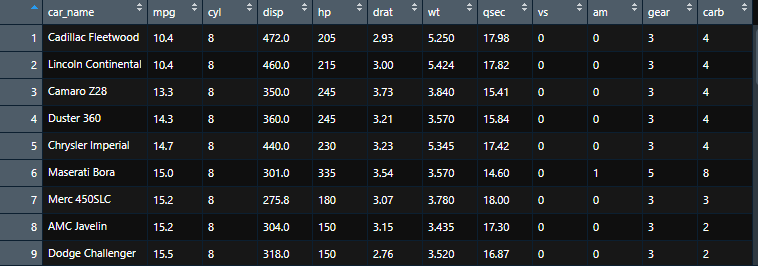
1974 년 Motor Trend US 잡지에서 발췌된 자동차 데이터에서는 Cadillac Fleetwood와 Lincoln Continental 이 가장 낮았네요. 만약 연비가 높은 순으로 보고싶다면 arrange(desc(mpg)) 를 입력합니다.
이번엔 mutate 함수를 이용하여 열을 추가해보겠습니다. 위에서 보았듯이 arrange 함수를 적용하니 자동차 명이 사라졌었는데 이 부분을 mutate함수를 이용해 자동차 명에 대한 열을 새로 생성하겠습니다.
test1 <- mtcars %>% arrange(mpg) %>% mutate(car_name = row.names(mtcars))
test1

결과가 나오긴했지만 car_name 이라는 열이 맨 뒤에 추가되었기 때문에 보기에는 불편합니다. 이 전에 포스팅했던 select함수를 쓰겠습니다. select함수는 변수의 순서를 결정할 수도 있습니다. 먼저 car_name 이라는 변수를 가장 앞에 놓고싶기 때문에 select 함수의 첫 번째로서 car_name 을 입력하고 그 뒤에는 mpg부터 carb 변수를 지정한다는 의미에서 mpg:carb 를 입력합니다.
test2 <- test1 %>% select(car_name,mpg:carb)
test2
mutate함수는 사칙연산을 통해 새로운 파생변수를 만들어낼 수도 있습니다. 예를 들어 자동차 무게(wt)에 대한 연비(mpg) 의 비율을 구해보면 다음과 같습니다.
test3 <- test2 %>% mutate(ratio = mpg/wt)
test3

결과를 보니 끝에 ratio 라는 열이 추가되었네요. 값들을 보니 연비가 낮을수록 ratio가 낮다는 추측을 해볼 수 있을 것 같습니다. 그 뜻은 자동차 무게가 많이 나가는 것에 비해 연비의 효율이 떨어진다고 이해할 수 있습니다. 이렇게 새로운 파생변수를 생성하여 그 의미를 파악해볼 수도 있습니다.
dplyr 패키지의 arrange 와 mutate함수에 관해 다루었는데요
궁금한점이 있으면 아래 댓글로 남겨주세요!
'데이터 분석 > R 데이터 처리 & 분석' 카테고리의 다른 글
| R 결측치 처리하기(is.na, complete.cases 등) (0) | 2020.06.13 |
|---|---|
| [데이터처리] 중복 데이터 제거한 데이터프레임 생성(duplicated, unique, distinct) (0) | 2020.05.17 |
| [R데이터분석] dplyr 패키지를 활용한 데이터전처리(2) (group_by, summarise) (0) | 2020.01.31 |
| [R데이터분석] dplyr 패키지를 활용한 데이터전처리(1) (0) | 2020.01.29 |
| [R데이터분석] factor함수 범주형 변수 다루기 (0) | 2020.01.23 |